M3-IT.github.io
M³IT: Multi-Modal Multilingual Instruction Tuning Dataset
📃[Paper] 💾[Dataset (En, Zh)] [Dataset (80 Languages Evaluation Set)] 🎇[Demo(Coming Soon)]
TL;DR
We introduce the Multi-Modal, Multilingual Instruction Tuning (M3IT) dataset, comprises 40 carefully curated datasets, including 2.4 million instances and 400 manually written task instructions, reformatted into a vision-to-text structure.
Key tasks are translated into 80 languages with an advanced translation system.
We train a VLM model on our M³IT dataset, showcasing its potential to answer complex questions, generalize to unseen video tasks, and comprehend unseen instructions in Chinese.
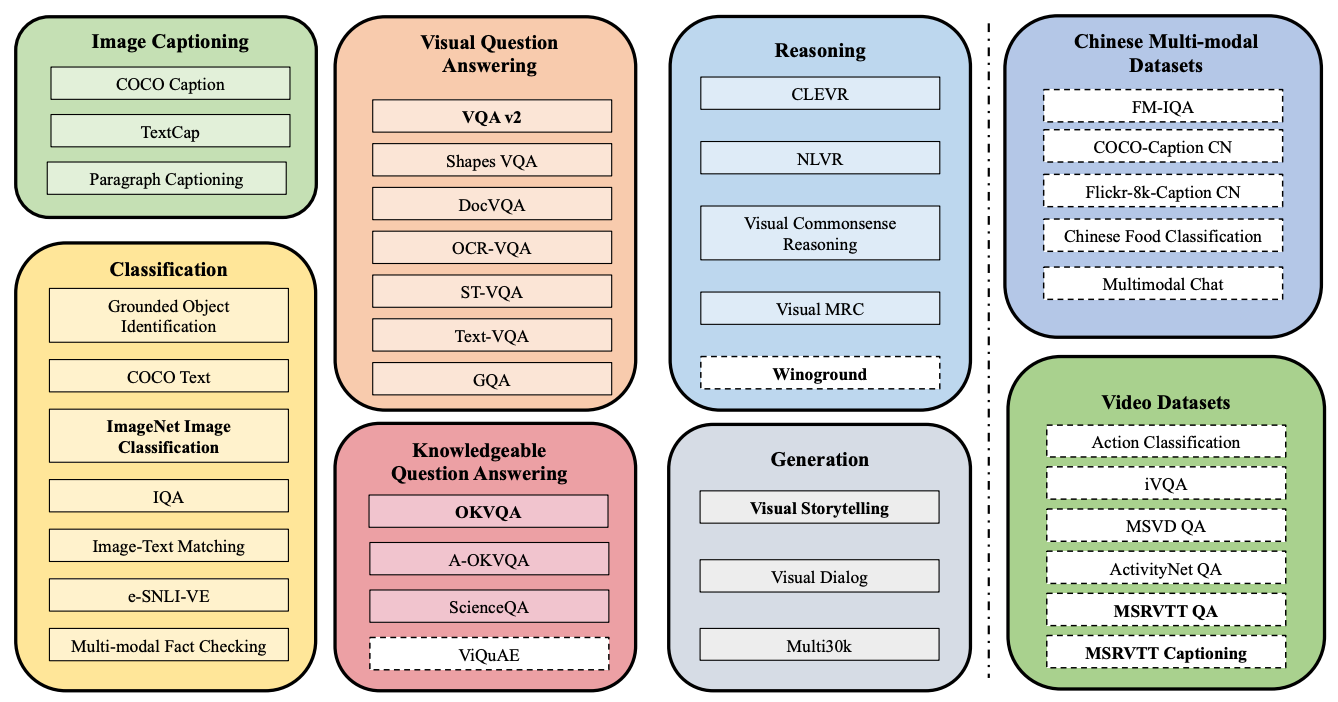
Task Coverage
Our dataset covers 40 diverse Vision-to-Text Task, featuring Chinese and Video tasks as well:
Dataset Instance
Our data instance looks like:

and you easily load the dataset and start training with your own model:
from datasets import load_dataset
from io import BytesIO
from base64 import b64decode
from PIL import Image
ds_name = "viquae" # change the dataset name here
dataset = load_dataset("MMInstruction/M3IT", "viquae")
for train_instance in dataset['train']:
instruction = train_instance["instruction"] # str
inputs = train_instance["inputs"] # str
outputs = train_instance["outputs"] # str
image_base64_str_list = train_instance["image_base64_str"] # str (base64)
image_0 = Image.open(BytesIO(b64decode(image_base64_str_list[0])))
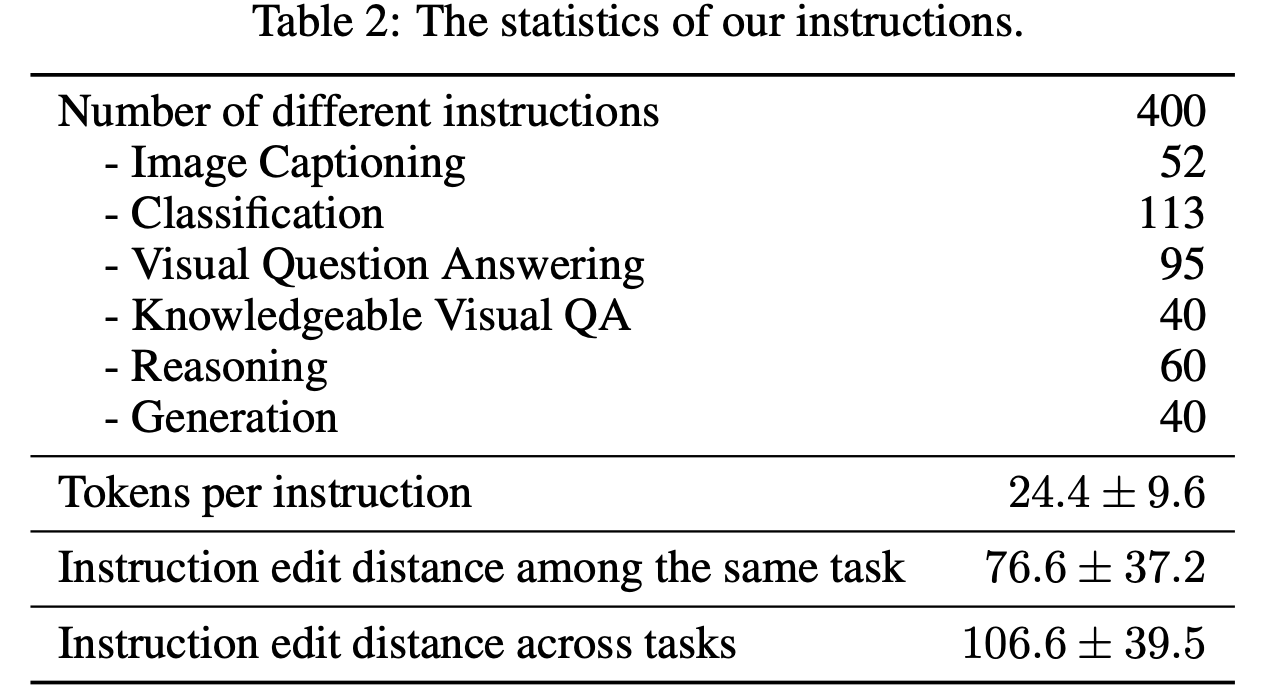
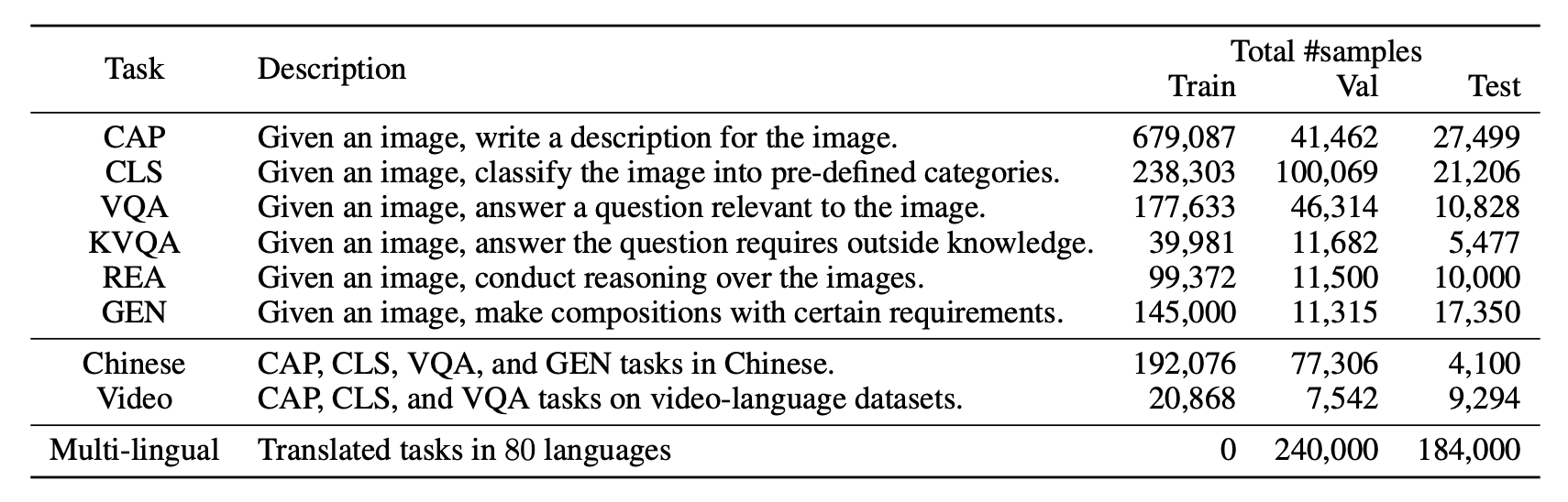
Statistics
Statistics of our instructions:
Statistics of our dataset grouped by task:
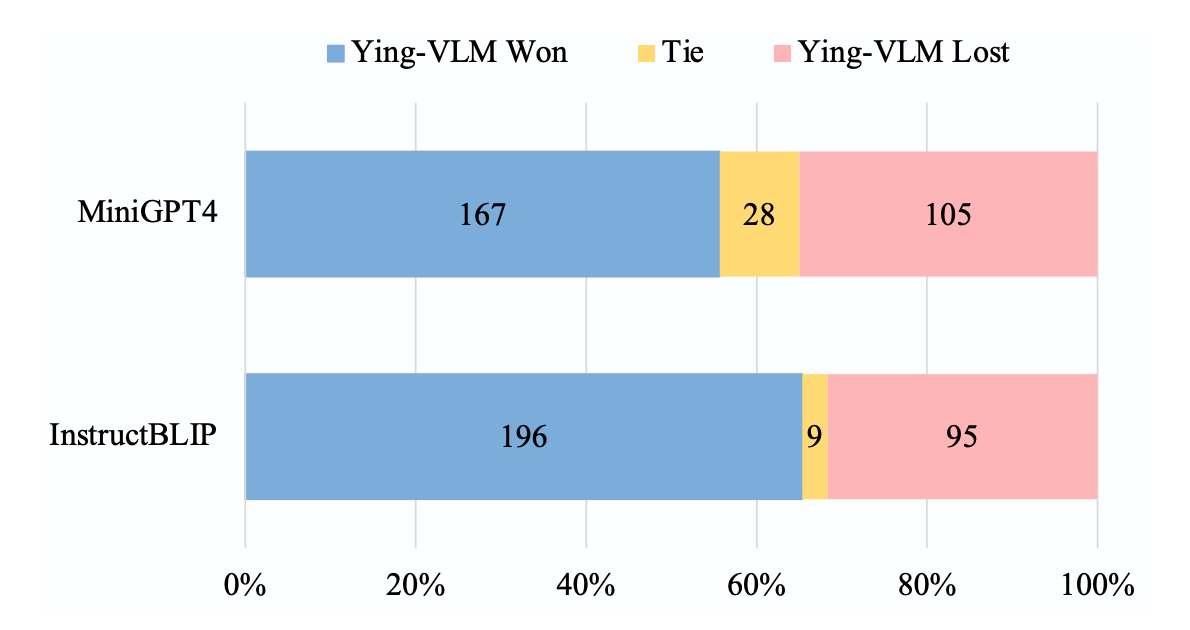
Model Evaluation
GPT-4 evalaution using FairEval on 300 instances from OK-VQA, A-OKVQA and ViQuAE, where our model outperforms MiniGPT4 and InstructBLIP in most cases.
Case study shows VLM trained our models provide accurate answers for challenging questions, and respond correctly to Chinese instructions!

BibTex
@article{li2023m3it,
title={M$^3$IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning},
author={Lei Li and Yuwei Yin and Shicheng Li and Liang Chen and Peiyi Wang and Shuhuai Ren and Mukai Li and Yazheng Yang and Jingjing Xu and Xu Sun and Lingpeng Kong and Qi Liu},
journal={arXiv preprint arXiv:2306.04387},
year={2023}
}